Content Strategy Best Practices for “Source” Structured Content
Khaled A.B. Aly, Technical Author and Analyst
The CSA “Best Practices Handbook” primary concern is to streamline the lifecycle management of large corporate sites and intranets from inception through planning, assessment, analysis, design, and maintenance phases. Typical web content would be generated by a CMS (like WordPress, Joomla, Drupal …) to HTML5/CSS, supported by web scripting languages (JavaScript and PHP) and a suitable metadata standard (e.g. Dublin Core, schema.org …). The CMS development work is to a large extent invisible to the content strategist.
On another hand, it is now widely agreed that the OASIS standard DITA (Darwin Information Typing Architecture), is the XML language of choice for structured documentation and e-learning source content (with over 400 element types). The standard expands as driven by market merit to cover other content types that may take advantage of its principal feature, that is: separating content, style, and publishing format. The open DITA standard and toolkit allow the enterprise to produce and setup own specialized vocabularies to cover specific domains such as heavy industry, hardware and semiconductors, pharmaceuticals, and others with merit for structured source. Following is a summary of the most basically distinguished features:
- Topic-orientation & strong semantic typing: Content is contained within typed topics that in-turn contain typed elements (corresponding to HTML layout tags), with much attention to modularity and minimalist authoring. Topics are hierarchically arranged within maps that allow as well building relation tables among topics and their content elements to support navigation.
- Multi-channel publishing (aka single-sourcing): The same DITA source markup could be published to formats meant to deliver print (e.g. PDF), HTML websites and other derivatives such as WebHelp, e-book HTML-based EPUB, and SCORM (Sharable Content Object Reference Model; the XML e-learning standard), as well as any XML-based format. Publishing to each medium is established through specialized transformation processors that take into consideration the respective style of source content to be rendered.
- Conditional publishing: Special DITA filtering attributes flag transformation engines of conditional inclusion, exclusion, or differentiated styling of any chunk of DITA content at any level: from a single phrase to a complete topic.
The CSA Handbook mainly pertains to Web content from a high-level content management perspective, regardless of how it had been developed. Structured DITA strategy and best practices are concerned with unprocessed, semantically typed, content that may be transformed to HTML (mainly to a WebHelp format that best supports documentation, but could be as well to a generic website template), and/or other forms. DITA content strategy best practices actually precede these supporting the finished site or publication (as would strategies for CMS-based site development), since DITA markup is source content that is yet to be transformed to a displayable form. This article explores a suitable compilation of strategic DITA-to-HTML best practices, for the three highest merit publishable forms: HTML website (template), WebHelp, and EPUB, as illustrated in the schematic below.
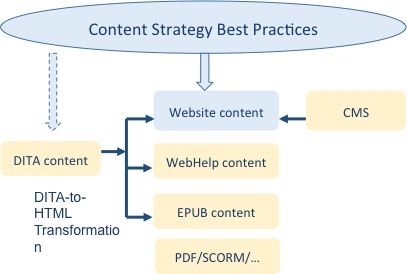
The following high-level categories are identified. [1], [2], [3]
- Content Modeling: content domain, specialization merit, choice of topic and element types
- Content Design: minimalist writing practices, reuse levels strategy, linking strategy
- Content Findability: taxonomy and metadata (DITA, Dublin Core, schema.org)
- Content Publishing: output formats, conditional publishing, transformation scenarios
- Content Management: workflow (process), change management, metrics, overall governance
References
- Laura Bellamy, Michelle Carey and Jenifer Schlotfeldtm, “DITA Best Practices: A Roadmap for Writing, Editing, and Architecting in DITA,” IBM Press, September, 2011
- Ann Rockley and Charles Cooper, “Managing Enterprise Content: A Unified Content Strategy,” New Riders, February, 2012
- Mark Lewis, DITA Metrics 101: The Business Case for Intelligent Content, Rockley Publications, January, 2013